力扣链接:833. 字符串中的查找与替换,难度:中等。
你会得到一个字符串 s (索引从 0 开始),你必须对它执行 k 个替换操作。替换操作以三个长度均为 k 的并行数组给出:indices, sources, targets。
要完成第 i 个替换操作:
- 检查 子字符串
sources[i]是否出现在 原字符串s的索引indices[i]处。 - 如果没有出现, 什么也不做 。
- 如果出现,则用
targets[i]替换 该子字符串。
例如,如果 s = "abcd" , indices[i] = 0 , sources[i] = "ab", targets[i] = "eee" ,那么替换的结果将是 "eeecd" 。
所有替换操作必须 同时 发生,这意味着替换操作不应该影响彼此的索引。测试用例保证元素间不会重叠 。
- 例如,一个
s = "abc",indices = [0,1],sources = ["ab","bc"]的测试用例将不会生成,因为"ab"和"bc"替换重叠。
在对 s 执行所有替换操作后返回 结果字符串 。
子字符串 是字符串中连续的字符序列。
示例 1:

输入: s = "abcd", indices = [0,2], sources = ["a","cd"], targets = ["eee","ffff"]
输出: "eeebffff"
解释:
"a" 从 s 中的索引 0 开始,所以它被替换为 "eee"。
"cd" 从 s 中的索引 2 开始,所以它被替换为 "ffff"。
示例 2:
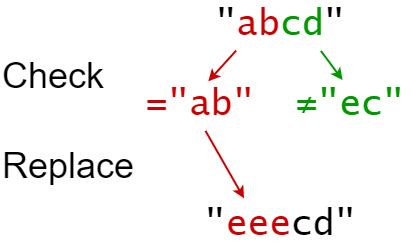
输入: s = "abcd", indices = [0, 2], sources = ["ab","ec"], targets = ["eee","ffff"]
输出: "eeecd"
解释:
"ab" 从 s 中的索引 0 开始,所以它被替换为 "eee"。
"ec" 没有从原始的 S 中的索引 2 开始,所以它没有被替换。
约束:
1 <= s.length <= 1000k == indices.length == sources.length == targets.length1 <= k <= 1000 <= indexes[i] < s.length1 <= sources[i].length, targets[i].length <= 50sconsists of only lowercase English letters.sources[i]andtargets[i]consist of only lowercase English letters.
思路
这道题目看起来简单,做起来还挺花时间的。
问题一:对于所求的目标字符串
result,可以基于原字符串的克隆,也可以从空字符串构建,哪个更好呢?
点击查看答案
基于原字符串的克隆比较好。因为你省去了不少子字符串的赋值操作。
问题二:在用
targets[i]替换result的子字符串后,result的长度可能会变化,这导致后面的替换变得困难。如何解决?
点击查看答案
用技术手段让
result的长度,在经历字符串替换后,始终保持不变。
复杂度
时间复杂度
O(N)
空间复杂度
O(N)
解释
N = s.length
Python #
class Solution:
def findReplaceString(self, s: str, indices: List[int], sources: List[str], targets: List[str]) -> str:
result = list(s)
for i in range(len(indices)):
index = indices[i]
if s[index:index + len(sources[i])] == sources[i]:
for j in range(index, index + len(sources[i])):
if j == index:
result[j] = targets[i]
else:
result[j] = ''
return ''.join(result)